

Most salon owners run tests backwards. They change their deposit policy on a Tuesday, watch bookings for two weeks, then declare victory or failure based on gut feel. That's not testing—that's just gambling with your operations.
A proper salon A/B testing framework doesn't require fancy analytics software or a statistics degree. What it does require is discipline around sample sizes, clear stopping rules, and templates you can actually execute between color appointments. The failures almost always come from the same place: testing too many things at once, with too few observations to draw real conclusions.
The minimum viable test: deposit experiments that actually tell you something
Deposit testing reveals the core challenge of salon experimentation. You want to know if requiring a $50 deposit for balayage appointments reduces no-shows without tanking bookings. Most salons flip the policy on for everyone and watch what happens. That tells you nothing useful.
Split your booking channels first. If 60% of appointments come through online booking and 40% through phone, test deposits on just the online channel initially. This gives you a natural control group without confusing staff or clients.
For a typical salon doing 300–400 monthly appointments, you need roughly 150 bookings in each group (deposit vs. no deposit) before drawing any conclusions. At that volume, if your baseline no-show rate sits around 8%, you can reliably detect whether deposits drop it to 4% or lower. Anything under 150 bookings per group and you're reading tea leaves.
The math matters because variance kills small samples. Say you normally see 8 no-shows per 100 bookings. In a group of just 50 bookings, random chance alone could produce anywhere from 2 to 8 no-shows. That spread makes it impossible to know if your deposit policy actually changed behavior or if you just had a quiet week.
Track these metrics for each group:
-
Total bookings attempted
-
Bookings completed (client paid deposit)
-
Booking abandonment rate
-
No-show rate for completed bookings
-
Average service value
-
Rebooking rate post-service
Decide your stopping rules before you start. If deposit bookings drop below 70% of normal volume in the first week, stop the test—you're losing too much revenue to keep going. If you hit 150 bookings per group with no clear difference in no-shows, deposits probably aren't your answer.
Rebooking script tests: measuring words that move the needle
Testing rebooking scripts requires different mechanics than deposit experiments. You can't A/B test scripts by stylist—they'll naturally drift toward whatever feels comfortable. Instead, test by time period or specific service type.
Stop losing appointments in the chaos.
Salnly helps you book, confirm & manage every appointment—efficiently.
- Centralized appointment management
- Client notifications
- Calendar & staff scheduling
No credit card required
Week A uses your current rebooking approach. Week B implements a new script with specific trigger points. Alternate weekly for 6–8 weeks minimum. This rotation controls for seasonal patterns while giving each approach enough volume to show real differences.
A functional rebooking script test template:
Current approach (Control): "Would you like to book your next appointment?"
Test approach: "I have [specific date/time] available for your next color—should I reserve that now so you don't lose your preferred slot?"
Track rebooking rate by:
-
Stylist (even though they're all using the same script)
-
Service type
-
New vs. returning client
-
Day of week
-
Time of day
For a salon with 8 stylists each seeing around 15 clients weekly, you'll generate roughly 240 observations per two-week period. That's enough to spot a 10% lift in rebooking rates with some confidence. Smaller improvements need longer test periods.
The stopping rule: if a script causes visible client friction—complaints, awkward interactions flagged by multiple stylists—kill it immediately, regardless of the numbers. Some operational improvements aren't worth the relationship cost.
Promotion cadence experiments: finding the sweet spot between engagement and annoyance
Promotion frequency is probably the most overtested and undertested aspect of salon marketing at the same time. Owners constantly tweak their schedule but rarely measure it systematically.
The right test structure for promotions starts by segmenting your client base by visit frequency:
-
Monthly visitors (your regulars)
-
Quarterly visitors (maintenance clients)
-
Twice-yearly visitors (special occasion only)
-
Lapsed (6+ months)
Each segment needs different testing parameters.
Monthly visitors: Test promotion frequency between 1x monthly vs. 2x monthly. You need 100+ clients per test group and should run for at least 3 months. Watch for booking fatigue—if redemption rates drop below 5% or unsubscribe rates triple, you're overcommunicating.
Quarterly visitors: Test 4-week vs. 6-week vs. 8-week promotion cycles. These clients need reminders, not bombardment. With typical salon list sizes, you'll need 4–6 months to accumulate enough data.
Lapsed clients: Test aggressive win-back sequences (3 touches in 2 weeks) vs. gradual reengagement (monthly touch for 3 months). Minimum 200 lapsed clients per group, measure reactivation within 60 days.
The sample size challenge with promotions comes down to redemption rates. If only 8–12% of recipients typically book from promotions, you need much larger test groups to detect meaningful differences. A 2% lift (from 10% to 12% redemption) requires roughly 800 recipients per test group to confirm it's not just random variation.
Statistical stopping rules without the statistics degree
The question isn't just when you have enough data—it's when you have enough of a difference to make a decision. Clear stopping rules prevent two costly mistakes: killing winners too early and running losers too long.
For binary outcomes (booked/didn't book, showed/no-showed), use this simple framework:
Clear winner threshold: When one approach beats another by 20% or more (relative difference) after hitting minimum sample size, implement the winner. Example: if deposits reduce no-shows from 8% to 6%, that's a 25% relative improvement—clear winner.
Clear loser threshold: When testing causes 30% or greater degradation in a critical metric, stop immediately. Doesn't matter if you haven't hit sample size yet. If new deposit requirements tank your booking rate from 80% to 55%, you don't need more data.
Inconclusive threshold: When you hit 2x your minimum sample size with less than 10% relative difference, call it inconclusive. The approaches are functionally equivalent—pick the simpler one to operate.
For continuous metrics (average ticket, service time, retail attach rate), the rules shift a bit. Look for at least 15% relative improvement to justify operational changes. A rebooking script that lifts rates from 60% to 63% probably isn't worth retraining your whole team over. One that moves 60% to 70% is.
Watch variance alongside averages too. If a new process increases average ticket by $15 but makes individual tickets wildly unpredictable, that instability might outweigh the revenue gain.
Building test templates your team will actually use
Templates fail when they demand too much from busy people. Your receptionist answering phones during Saturday rush isn't going to fill out a 12-field tracking sheet. Build templates that capture essential data without disrupting operations.
Deposit test tracking template:
Simple spreadsheet with daily entries:
-
Date
-
Online bookings attempted (from system)
-
Online bookings completed (deposit paid)
-
Phone bookings (total)
-
No-shows online (with deposit)
-
No-shows phone (without deposit)
-
Notes (system issues, unusual events)
That's it. Takes 3 minutes at end of day. Run for 30 days, compare groups, make a decision.
Rebooking script tracker:
Even simpler—stylists put a hash mark in one of three columns after each appointment:
-
Rebooked same service
-
Rebooked different service
-
Declined rebooking
Weekly totals get entered into the master sheet. No individual client tracking needed.
Promotion response template:
Pull from your booking system:
-
Send date
-
List segment
-
Recipients
-
Opens (if tracked)
-
Bookings within 7 days
-
Revenue from those bookings
Keep deposit and rebooking templates to one small sheet so staff actually complete them.
Calculate response rate and revenue per recipient. Compare test groups monthly.
Real operational examples with actual results
A 4-chair salon ran a structured rebooking test for 12 weeks, alternating between their standard "want to book next time?" approach and a specific appointment offering. Standard approach: 47% rebooking rate across 312 clients. Specific offering: 61% rebooking rate across 298 clients.
That 30% relative improvement looked massive until they dug deeper. The specific appointment approach worked great for regular color clients (45% to 72% rebooking) but actually decreased rebooking for occasional haircut-only clients (38% to 29%). The real insight: segment the approach by service type rather than using one script universally.
Another salon tested deposit requirements on color corrections only—their highest no-show category. Baseline no-show rate was 14%, which is brutal for 3-hour appointments. With $75 deposits, it dropped to 4%. But the data also showed 22% booking abandonment when deposits were required.
Running the math: losing 22% of bookings to prevent 10% no-shows only makes sense if those abandoned bookings were likely no-shows anyway. They surveyed abandoned bookings and found 80% were first-time clients shopping around for quotes. Decision: keep deposits, but improve the pre-booking explanation about why they're required.
How a deposit test actually flows from start to finish
Most salons understand the concept of A/B testing but struggle to visualize how the sequence actually runs in practice. Here's the decision flow for a typical deposit experiment:
Start Test │ ▼ Split Booking Channel (Online = Deposit Group / Phone = Control Group) │ ▼ Run for 30 Days │ ├──► Deposit bookings drop below 70% of normal volume? │ │ │ ▼ │ STOP TEST — too much revenue loss │ ├──► Hit 150 bookings per group? │ │ │ ▼ │ Compare no-show rates │ │ │ ├──► 20%+ relative improvement → Implement deposit policy │ │ │ ├──► Less than 10% difference at 2x sample → Call it inconclusive │ │ │ └──► 30%+ degradation in booking rate → Kill the test │ └──► Still under minimum sample? → Keep running.
Flowchart of the deposit test process.
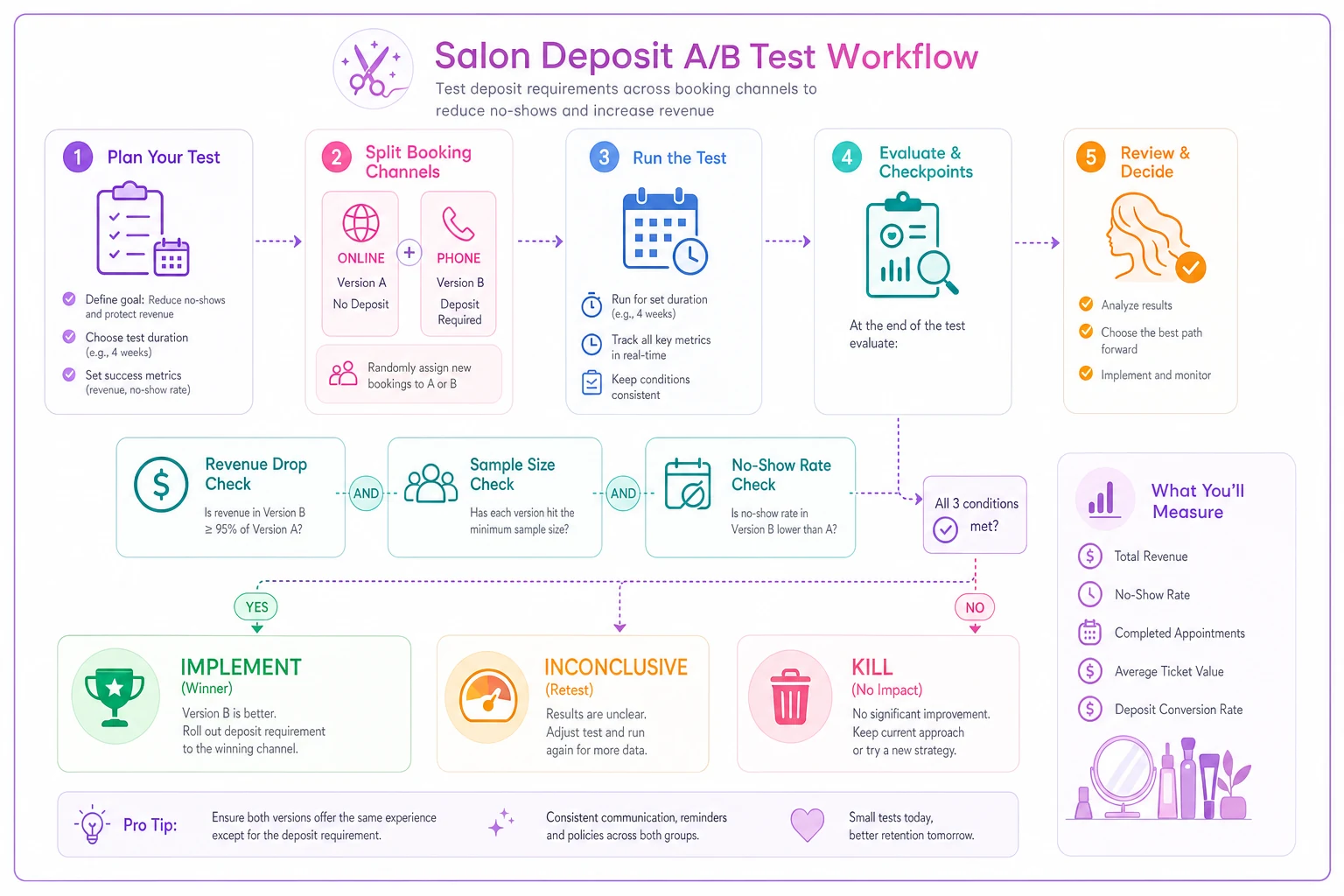
This kind of sequential decision structure is where AI-powered operational software can genuinely help. Instead of manually checking spreadsheets each morning, platforms with automation built in can flag when a test crosses a stopping threshold—so you're not accidentally running a losing test an extra two weeks because nobody noticed the numbers had already told you the answer.
When A/B testing wastes time (and when it doesn't)
Not everything needs a controlled test. If clients are regularly complaining about something, fix it. If you're losing stylists, deal with retention. Save testing for genuine uncertainties where multiple reasonable approaches exist.
Good testing candidates:
-
Pricing changes (test on specific services first)
-
New service bundles
-
Communication timing
-
Booking flow modifications
-
Upsell techniques
Bad testing candidates:
-
Safety protocols
-
Legal compliance issues
-
Basic customer service standards
-
Emergency procedures
Realistically, you can run 3–4 meaningful tests annually without overwhelming your team. Pick the ones targeting your biggest revenue gaps or operational pain points.
Interpreting results when the data gets messy
Real salon data never looks like textbook examples. You'll test a new confirmation sequence during the week a snowstorm hits. Your control group will include the week your best stylist went on vacation. The data gets messy, but patterns still emerge if you collect enough observations.
Look for consistency across multiple metrics. If deposits reduce no-shows, you should also see higher revenue per booked appointment and probably better on-time performance. If you only see improvement in one metric while others stay flat or dip, dig deeper before drawing conclusions.
Weight results by business impact. A 5% improvement in rebooking for high-ticket color clients matters more than a 15% improvement for bang trims. Calculate actual revenue impact, not just percentages.
Factor in operational complexity too. A promotion strategy that lifts bookings by 12% but requires three email sequences, two text campaigns, and daily manual tracking might not actually beat a simpler approach delivering 8% lift through one automated flow.
Building your testing calendar without overwhelming operations
Map tests to your natural business cycles. Test deposit policies during steady months—not December or August. Test promotional frequency during shoulder seasons when you need bookings most. Rebooking scripts work well to test after New Year when clients are forming new habits anyway.
A realistic annual testing calendar:
| Quarter | Test Focus | Duration |
|---|---|---|
| Q1 | Rebooking script optimization | 8 weeks active testing |
| Q2 | Deposit policy for specific services | 6 weeks testing, 4 weeks rollout |
| Q3 | Promotion frequency for lapsed clients | Full quarter |
| Q4 | Hold for holidays—implement winning tests from the year | — |
This gives each test breathing room without losing momentum. You're always testing something but never juggling multiple experiments that could interfere with each other.
Track test history carefully. Document not just what won, but what you tested, when, sample sizes, and why you stopped. That record prevents re-testing failed ideas and helps new managers understand what's already been figured out.
Actioning winners and killing losers
The test ends, you have a winner—now what? Implementation usually fails because winning tests get watered down during rollout. That rebooking script that lifted rates 20% becomes "say something about rebooking" within two weeks.
Codify winning approaches immediately:
-
Update written SOPs
-
Create laminated reference cards
-
Build the winning approach into your booking system where possible
-
Schedule refresher training monthly for the first quarter
For losing tests, document why they failed. Was it client resistance? Operational complexity? Unexpected side effects? That failure library becomes as valuable as your successes—it stops future teams from repeating expensive mistakes.
Some tests will just confirm your current approach already works. That's a valid outcome. Knowing your existing process beats competitors' "best practices" builds team confidence and cuts down on random changes driven by whatever the latest industry blog post recommends.
The compound effect of systematic testing
Running three solid tests annually might seem minimal, but the compound effect adds up. Year one you optimize deposits, rebooking, and confirmation timing—maybe 15–20% total improvement across key metrics. Year two you layer on pricing tests, service bundling, retail attachment—another 10–15% gain.
By year three, you're operating at a completely different level than competitors still making changes based on feelings. Your decisions come from data, not desperation. Your team trusts changes because they've seen the process work.
More importantly, you've built a testing culture. Staff suggest test ideas. They track results naturally. They push back on changes that haven't been validated. That cultural shift matters more than any individual test result.
The framework here strips away the complexity that stops most salons from testing systematically. You don't need an analytics team or enterprise software. You need clear templates, reasonable sample sizes, and the discipline to follow through. Salons consistently growing revenue per chair aren't lucky—they're just more systematic about finding what works and scaling it.
The framework here strips away the complexity that stops most salons from testing systematically. You don't need an analytics team or enterprise software. You need clear templates, reasonable sample sizes, and the discipline to follow through. Salons consistently growing revenue per chair aren't lucky—they're just more systematic about finding what works and scaling it.
Ready to simplify your salon operations?
Join 1,000+ salons using Salnly to save time, reduce scheduling chaos, and deliver better client experiences.


